

abaqus最新版本好不好? 2022x新功能介绍第三弹-博天堂登陆
abaqus线性分析的功能增强
(一)线性动力学的功能增强
1. 模态分析中增加connector单元的输出
模态线性动力学分析中增加下列connector单元的输出,无需指定* connector motion即可实现:axial,bushing,cardan,cartesian和rotation。
而且改进了ctf输出变量在之前版本的模态叠加分析步中所有connector单元类型都无法输出的情况。
2.提高了响应谱分析性能
改进了响应谱分析中使用下列计算密集型模态求和方法进行单元结果恢复时的性能,例如完全二次组合法 (cqc)、双和组合法 (dsc)、分组方法(grp)。
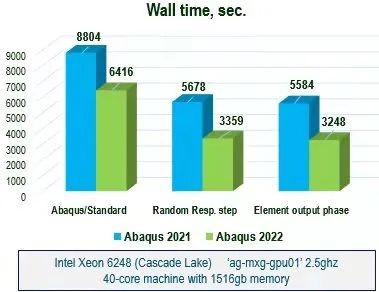
3.随机响应分析的功能增强
之前版本中rms mises应力不是在abaqus/standard中计算的,而是在abaqus/viewer中计算。大量的输出数据(特征应力,广义位移)必须存储在输出数据库中。rms mises应力计算在大规模模型分析中的应用效果并不理想。计算出的rms mises应力不会存储在输出数据库中。新版本中提高了随机响应分析中单元结果计算的性能。而且在abaqus/standard中实现rms mises应力计算。
(二)线性方程及迭代求解器的功能增强
1.使用ams解决大规模的特征问题
新版本可以支持超过20亿非零项的大规模模型,实现了在smp模式下支持大规模模型的求解。在smp机器上大规模模型的单元计算不能使用多cpus,但求解器可以并行求解,用法如下:abaqus job=jobname standard_parallel=solver
之前版本中热交换器的模型因超过20亿个非零项而运行失败。但在40核和1.5tb内存的机器上,abaqus r2021xfd07/r2022xga能够顺利运行并完成求解。

2.ams特征求解器的gup加速
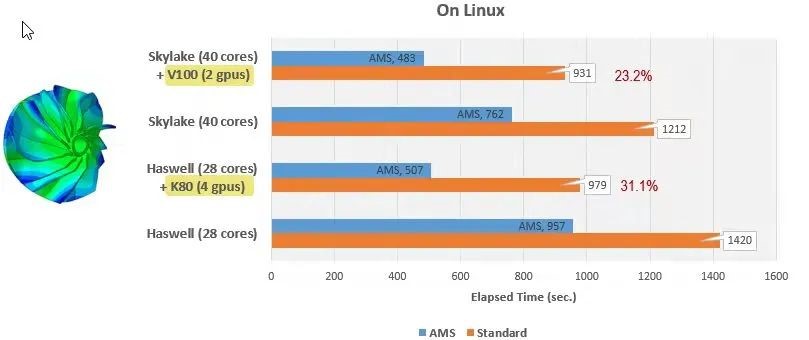
在abaqus r2020xfd02/r2021xfd01中能够在windows hpc机器上启用gpu加速,改善了linux上的性能。在r2022xfd02之后支持最新的英伟达ampere card(a100),需要升级cuda和magma库以支持a100。例一为benchmark的叶轮模型,820万dof,在linux机器上提取86阶模态结果,gpu显著提高了ams特征求解器的性能。
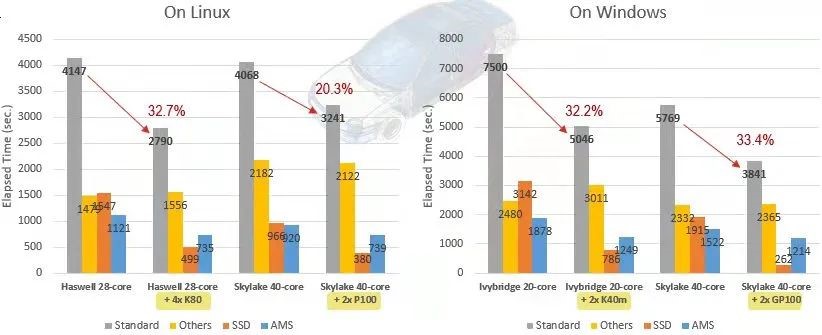
另外,gpu加速稳态动力学ssd求解器。例二为整车模型,1750万dof,分别运行在linux和windows机器上提取10900阶模态结果,再进行ssd仿真分析。
3.迭代求解器(lterative solver)功能增强
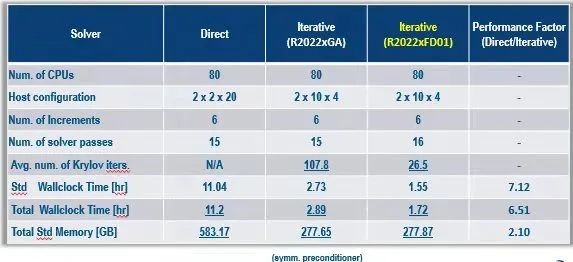
在r2022xfd01中增加了非对称迭代求解器的新实现方式,使用新的krylov迭代求解器,并增强了amg代数多重网格预处理程序和mcp混合约束预处理程序来支持非对称求解,能够处理明显的非对称问题。以发动机模型为例,模型尺寸为5160万dofs和3.65e 15 flops,定义了多处的tie约束、螺栓预紧力、摩擦系数为0.2的接触对(罚函数法)和具有非线性法向行为的垫片,由于接触摩擦产生的不对称效应是明显的,执行unsymm=yes的静力学分析。

二、abaqus子结构的功能增强
1.子结构数据库设计
这个版本对子结构数据库功能进行了重大的重新设计,特别是:
● 取消了子结构库.sup文件。子结构.sim文件现在是子结构数据库的主文件。
● 您必须重新生成以前生成的所有子结构。
● 重新设计不会改变整个子结构工作流和结果。所有使用再生子结构的模型的运行方式与以前相同。
● 随着.sup文件的取消,作为多个子结构容器的 "子结构库 "的概念已经过时。因此,每个子结构数据库变成了一套完全独立的使用子结构名称生成的文件。你可以复制、重命名和删除这些文件。
keyword界面的改变包括:
● 与子结构库相关的选项被删除,如子结构复制*substructure copy, 子结构删除*substructure delete,以及子结构目录*substructure directory。
● 其他与子结构相关的选项(*substructure generate和*element) 仍然支持传统的子结构库id命名规则,但有不同的含义:library现在是子结构名称的前缀,id是后缀,结果子结构名称是library_zn。这个规则保证了与现有输入文件的向后兼容性。
● 新的参数可用于*substructure generate和*element选项,允许指定子结构的名称,该名称用于命名子结构数据库文件。名称值可以是任何有效的名称,包括library_zn。
● 目前支持新旧两种命名规则。强烈建议使用新的命名规则。
2.基于频率的子结构
使用直接稳态动力学分析和子结构生成分析的组合定义基于频率的子结构。
直接ssd分析与保留节点自由度相结合,在用户指定频率下生成基于频率的子结构的算子。
子结构生成的分析在合并子结构数据库中同时存储基于频率的子结构算子和常规子结构算子。
根据分析类型和子结构属性,使用一组或另一组算子。
可以在分布式内存并行 (dmp) 模式下生成基于频率的子结构,以便在大型模型中实现更好的可扩展性。
3.对非对称子结构的增强
在当前的子结构生成分析中无论是否使用对称或非对称求解器,都可以生成子结构解算器的对称、非对称或同时生成对称和非对称实例。

引入了一个新的选项,用法上通过控制结构刚度矩阵的对称和非对称实例的比例,进行参数化研究。此选项只允许在复杂频率提取分析中使用。

三、abaqus接触和约束功能增强
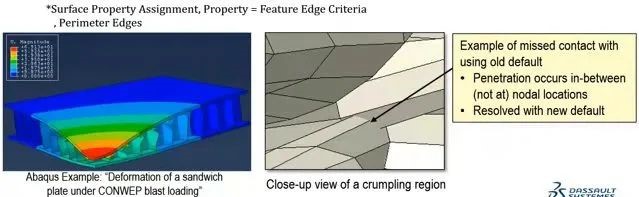
1.默认考虑接触特征边
explicit自动选择哪些边要考虑接触。提高了精确度和易用性,增加了少量(≈10%)额外的计算时间。在最近的版本中进行了开发和增强(现在默认情况下可以激活)。先前的默认值,仅考虑周长边和梁参考边所在的接触。
2.standard中通用接触动态分配接触单元和节点
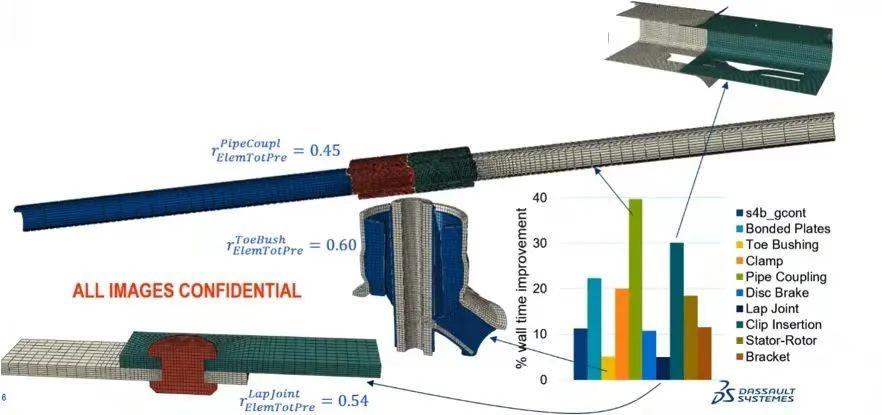
之前版本中针对接触单元和节点的大规模静态分配,由于它们中的大多数都是不激活的,显著影响了性能。如果静态分配不足,偶尔会发出错误消息。abaqus 2022 ga采用内部接触单元和节点的动态分配,避免了大量不激活的接触单元和节点,通常性能会提高10% 到20%。
当通用接触面上节点的比例很大,而且接触面节点的小部分在接触中是激活的,此时性能的改善往往是最显著的。
3.standard中通用接触中与分析步相关的接触
此功能允许用户为某一分析步暂停某个接触,类似于接触对中已有的model change功能,但使用不同的关键字来表征。
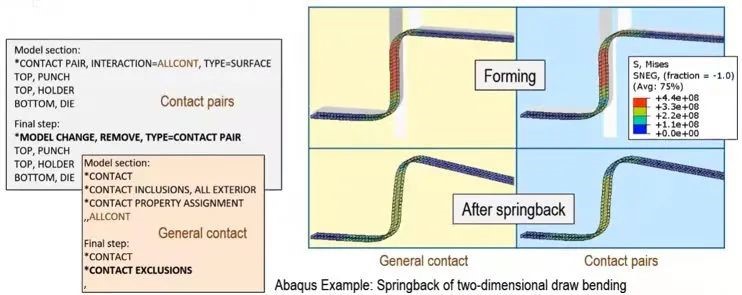
当需要在abaqus2022ga通用接触的模型级使用contact inclusions包含/引入接触时,必须指定仿真中可能接触区域的“包络线”。在模型部分中指定接触初始化,会延续到重新引入接触的分析步中,但优先使用在该分析步中指定的接触初始化。当接触重新引入时也可以对干涉配合进行建模。在分析步级中不允许使用无应变节点调整。
4.explicit改进了含c3d10单元的约束功能
解决了以前版本中遇到的稳定性和准确性问题,也避免了一些涉及c3d10单元的人为增加的质量约束。例如distributing coupling,基于面的tie约束。使用c3d10单元的基于面tie约束的实例对比如下:
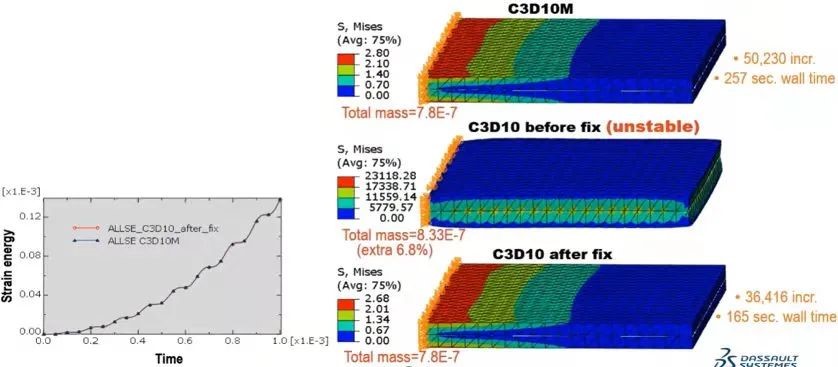
对于explicit中10节点四面体单元,演示仿真模型中c3d10相对于c3d10m,增量减少约28%,每个增量的处理时间提高了12%,仿真时间提高了37%。
5.explicit中约束的性能诊断
abaqus/explicit在大多数情况下能够精确地执行约束,有时需要每个增量求解隐式方程,即通常小于12个变量的线性方程。然而重叠约束(和connectors)可能导致大量非线性系统方程。如果每个处理器由一个cpu处理,就降低性能和并行扩展。
新的诊断方法主要处理大规模模型的案例。abaqus/explicit估算系统每次求解通过时的浮点操作(flops)。在不同flop阈值处发布信息,警告或者错误消息。而且会控制将这种类型的错误消息降级为警告消息。
6.explicit中非圆形截面梁的接触增强
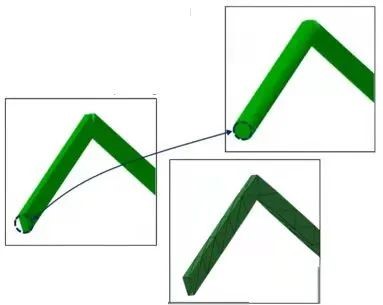
之前版本中已有梁截面的接触处理方法,无论梁或桁架单元的实际截面是什么,梁和桁架单元的接触边都具有圆形截面。接触边的半径等于截面周围最外圆的半径。新方法用于实现与实际横截面的接触行为。支持的梁截面包括多边形截面(arbitrary,box,hex,i,l,rect,trapeziod)和圆形截面(circ和pipe)
![]()
7.standard电自由度的界面电导和扩散
之前版本中无论接触开启或闭合默认使用零的界面传导。新版本中闭合状态的接触界面具有高的界面传导,自动选择数值来仿真计算。开启状态的接触界面默认为零的界面传导。
四、explicit技术和性能增强
1.co-simulation功能增强
增强的g&c算法现在可以在并行的耦合端运行。目的是处理结构到结构的强耦合,使用standard explicit耦合和simpack explicit 耦合。当耦合端子循环时,性能得到提高。小时的间增量的耦合端现在仅在目标时间点处随着指向交互。而且改进了映射性能。
联合仿真引擎(cse)的并行化正在不断发展。对于r2022xhf1,耦合端程序可以并行注册协同仿真区域,并行交换数据。因此,耦合端不再需要通过单个进程收集并与cse进行接口。
2.hybrid message parallelism (hmp)并行功能增强
首先快速回顾一下hmp用法:abaqus -cpus n -threads_per_mpi_process t -input …。新版中提高了高核数下的性能。成功测试了8000核的hmp。而且提高了mpi在dmp和hmp模式下的性能,及double=constraint执行的性能。进一步降低了packager的内存消耗,可以在节点上使用大约256gb内存处理7500万单元的模型。以abaqus/explicit 手机跌落模型测试为例,手机从1米高度跌落至坚硬的地板上,仿真周期:为冲击后1ms,模型中contact, plasticity, 和failure models呈现非线性行为。hmp通常在intel处理器上执行dmp。hmp使更高内核的使用更具吸引力。
丰田venza整车碰撞模型(e13.inp)的并行实例中,500万单元,2900万dof,模拟在时速35mph下碰撞40ms的时间,使用硬件环境为intel broadwell e5 2680 v4 2.4ghz 进行单精度计算。每个版本中都有性能的改进。







-
2024-05-24
-
2024-05-24
-
[abaqus] abaqus提交作业后一直中断是什么原因?
2024-05-24
-
[有限元知识] abaqus软件分析指南382:在静态或特征频率分析中指定
2024-05-24
-
[有限元知识] abaqus软件分析指南381:激活伴随灵敏度分析
2024-05-24
-
[有限元知识] abaqus软件分析指南380:伴随设计灵敏度分析
2024-05-24
-
[有限元知识] abaqus软件分析指南379:dsa918博天堂官网的解决方案局限性
2024-05-23
-
[有限元知识] abaqus软件分析指南378:dsa918博天堂官网的解决方案的准确性
2024-05-23
-
[有限元知识] abaqus软件分析指南377:线性扰动步长的数字减影算法
2024-05-23
-
[有限元知识] abaqus软件分析指南376:指定响应和请求响应
2024-05-22
-
2023-08-24
-
[abaqus] abaqus如何建模?abaqus有限元分析教程
2023-07-07
-
2023-08-29
-
[abaqus] 有限元分析软件abaqus单位在哪设置?【操作教程】
2023-09-05
-
[abaqus] 如何准确的评估真实行驶工况条件下的空气动力学性能
2020-11-19
-
[abaqus] abaqus单位对应关系及参数介绍-abaqus软件
2023-11-20
-
[abaqus] abaqus里面s11、s12和u1、u2是什么意思?s和
2023-08-30
-
2023-07-26
-
[abaqus] abaqus最新版本好不好? 2022x新功能介绍第一弹
2022-04-28
-
[abaqus] abaqus软件教程|场变量输出历史变量输出
2023-07-18
-
[有限元知识] abaqus软件分析指南382:在静态或特征频率分析中指定
2024-05-24
-
[有限元知识] abaqus软件分析指南381:激活伴随灵敏度分析
2024-05-24
-
[有限元知识] abaqus软件分析指南380:伴随设计灵敏度分析
2024-05-24
-
[有限元知识] abaqus软件分析指南379:dsa918博天堂官网的解决方案局限性
2024-05-23
-
[有限元知识] abaqus软件分析指南378:dsa918博天堂官网的解决方案的准确性
2024-05-23
-
[有限元知识] abaqus软件分析指南377:线性扰动步长的数字减影算法
2024-05-23
-
[有限元知识] abaqus软件分析指南376:指定响应和请求响应
2024-05-22
-
[有限元知识] abaqus软件分析指南375:直接设计灵敏度分析产品:a
2024-05-22
-
[有限元知识] abaqus软件分析指南374:设计敏感性分析
2024-05-22
-
2024-05-21
-
 汽车交通
汽车交通 -
 风能电源
风能电源 -
 船舶机械
船舶机械 -
 生物医疗
生物医疗
-
 土木建筑
土木建筑 -
 新能源
新能源 -
 高科技
高科技



地址: 广州市天河区天河北路663号广东省机械研究所8栋9层 电话:020-38921052 传真:020-38921345 邮箱:thinks@think-s.com



博天堂登陆 copyright © 2010-2023 广州思茂信息科技有限公司 all rights reserved. 粤icp备11003060号-2